Research Project
Towards Efficient High-Fidelity Video Generation at Ultra-Large Spatial Resolution
High-resolution video generation is limited by two coupled bottlenecks: unstable optimization and prohibitive computational cost. As the token sequence expands, optimization becomes biased toward local textures, weakening global coherence and increasing both training and inference cost.
PixelWizard addresses this by hierarchically decoupling global structure modeling from high-resolution detail synthesis. It first establishes a compact spatiotemporal anchor that concentrates dense structural priors, then uses this anchor to guide fine-grained synthesis at native high resolution.
To break the inference bottleneck, PixelWizard introduces Noise-Span Aligned Shortcut Training, together with Exponential Index-Biased Sampling and Adaptive Noise-Span Calibration. This enables robust few-step generation without memory-heavy teacher-student distillation.
From compact anchors to high-resolution detail
PixelWizard models global motion and layout in a compact high-density latent space, where long-range spatiotemporal structure is easier to optimize.
The generated anchor is injected into the DiT backbone as a structural prior, allowing high-resolution synthesis to focus on local textures and fine details.
A step-size-aware shortcut objective lets the model traverse the generation trajectory with large denoising steps while remaining stable on high-resolution grids.
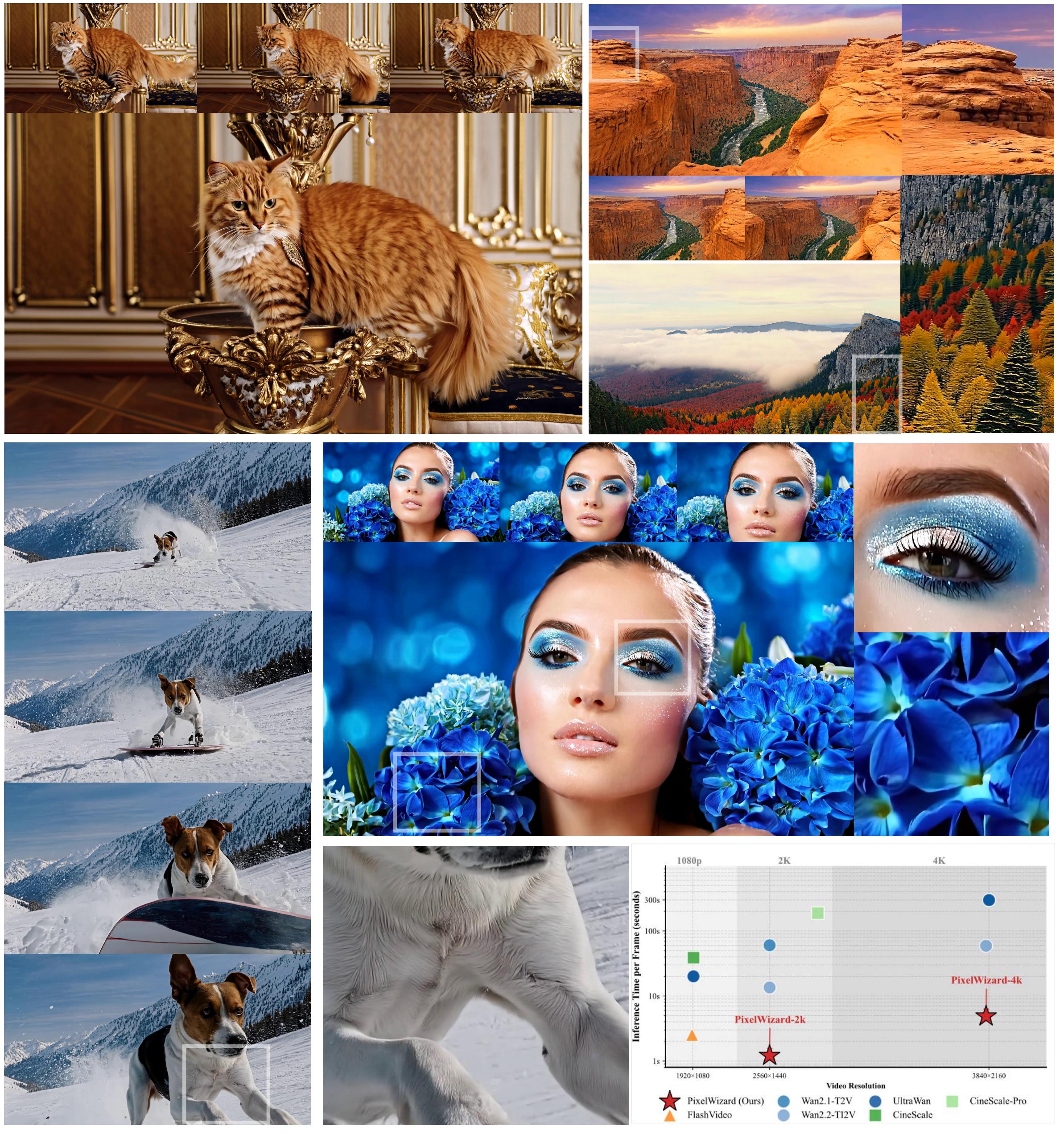
High visual quality with practical inference speed
121-frame videos with strong subject consistency and substantially lower latency.
Ultra-large spatial resolution with preserved coherent structures and fine local details.
Accelerated native 2K/4K sampling through few-step inference without distillation.
@misc{li2026pixelwizard,
title={PixelWizard: Towards Efficient High-Fidelity Video Generation at Ultra-Large Spatial Resolution},
author={Li, Wenxue and Ren, Jingjing and Zhang, Peng and Ye, Tian and Zhou, Daiguo and Luan, Jian and Zhu, Lei},
year={2026}
}